네트워크 계층에서의 패킷 즉 데이터그램은 특정한 형식에 맞게 만들어져 있습니다. 이번 글에서는 데이터그램의 형식에 대해 공부해보도록 하겠습니다.
1. 데이터그램의 형식
데이터그램은 헤더 부분과 상위 계층으로부터 받아온 데이터 부분으로 나누어집니다. 데이터 부분은 상위 계층에서 내려보낸 그대로 사용하고, 헤더 부분만 네트워크 계층에서 만들어 데이터 부분과 합쳐줌으로써 데이터그램을 만들어냅니다. 헤더의 형식은 아래와 같습니다.
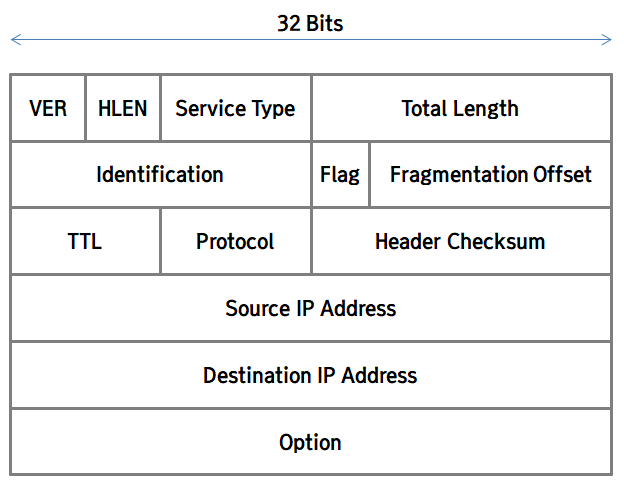
각 구성요소들에 대해 하나씩 살펴보도록 하겠습니다.
1. VER (Version): IP 프로토콜의 버전을 의미합니다. IP 프로토콜은 IPv4와 IPv6가 현재 사용되고 있으며, 4자리 비트로 이루어져 있기 때문에, IPv4의 경우 0100, IPv6의 경우에는 0110으로 표기됩니다.
2. HLEN (Header Length): 헤더의 길이를 알려주는 부분으로, 4 비트로 표현됩니다. 헤더는 헤더의 가장 마지막에 포함되는 옵션의 길이에 따라 옵션이 없으면 20바이트, 옵션이 최대로 추가되면 60바이트가 됩니다. 위의 그림에서는 옵션도 32비트인 것처럼 그려져 있지만, 경우에 따라 옵션 필드가 없을 수도, 훨씬 커질 수도 있습니다.
3. Service Type: 해당 데이터그램의 지연, 우선순위, 신뢰성, 처리량 등의 정보를 담고 있는 필드입니다. 8 비트로 이루어져 있습니다.
4. Total Length: 헤더와 데이터 부분을 합한 데이터그램의 전체 길이를 뜻합니다. 이 전체 길이 필드가 16 비트로 이루어지기 때문에, 데이터그램의 최대 길이는 2^16 -1, 즉 65,535비트(64KB)를 넘지 못합니다. 당연히 데이터 부분의 길이는 전체 길이에서 먼저 나온 헤더의 길이를 빼서 알아낼 수 있습니다.
5. Identification: 데이터그램은 상황에 따라 목적지에 도착하기 전에 여러 개로 나누어질 수 있습니다. 이렇게 데이터그램이 여러 개로 갈라졌을 때, 이 여러 개의 데이터그램들이 원래는 동일한 특정 데이터그램이었다는 식별자 정보를 이 곳에 저장합니다. 여기에 대해서는 밑에서 더 자세히 알아보도록 하겠습니다. 이 필드 역시 16 비트로 이루어집니다.
6. Flag, Fragmentation Offset: 각각 3개, 13개의 비트로 이루어져 있으며, 바로 위에서 설명한 데이터그램이 분리되는 것과 관련된 필드이기 때문에, 이 부분에 대해서도 밑에서 함께 알아보도록 하겠습니다.
7. TTL (Time to Live): TTL 필드는 쉽게 말해 수명을 알려주는 필드입니다. 데이터그램이 네트워크 상에서 다양한 이유로 목적지에 도착하지 못하고 네트워크를 떠도는 일이 생길 수 있습니다. 이런 길을 잃은 데이터그램들이 늘어나면, 네트워크의 흐름을 방해할 수 있고, 상위 계층을 혼란시킬 수 있기 때문에 수명을 다한 데이터그램들은 자동으로 폐기되게 됩니다.
TTL 필드에는 최초에 수명을 할당받은 뒤, 하나의 라우터를 통과할 때마다 숫자가 1씩 감소하며, 목적지에 도착하기 전에 1이 되면 해당 데이터그램은 폐기되게 됩니다. 일반적으로 예상 경로로 가는 길에 거쳐야 할 라우터 수의 2배 정도로 지정해줍니다. 8개의 비트로 이루어져 있습니다.
8. Protocol: 네트워크 계층의 상위 계층인 전송 계층이 사용하는 프로토콜에 대한 정보를 담고 있습니다. 8 비트로 구성되며, 대표적으로 UDP는 17, TCP는 6, ICMP는 1을 사용합니다. 각각의 프로토콜에 대해서는 전송 계층을 공부할 때 알아보도록 하겠습니다.
9. Header Checksum: 헤더 체크섬은 헤더에 오류가 있는지를 확인하기 위한 16비트로 이루어진 필드입니다. 데이터 링크 계층에서의 Error Control과 같은 역할을 한다고 볼 수 있습니다. 체크섬에 대해서도 아래쪽에서 더 자세히 알아보겠습니다.
10. Source / Destination IP Address: 각각 32 비트로 이루어지며 송신과 수신자의 IP 주소가 기록되어 있습니다.
2. 단편화와 재조립 (Fragmentation & Reassembly)
위에서 잠시 미뤄뒀던 단편화와 재조립에 대해 알아보겠습니다. 단편화는 하나의 데이터그램을 여러 개로 나누는 것이고 재조립은 이렇게 나누어진 데이터그램을 목적지에서 다시 하나로 합치는 과정입니다.
네트워크들은 각각 한 번에 보낼 수 있는 데이터의 최대 길이가 정해져 있습니다. 이를 MTU (Maximum Transmission Unit)이라고 합니다. 그래서 원하는 네트워크를 지나가기 위해서는 데이터그램을 MTU를 넘지 않는 크기로 잘라주어야 합니다. (물론 MTU를 넘지 않는다면 그냥 지나갈 수 있습니다.)
이를 위해 하나의 데이터그램을 같은 헤더를 가진 여러 개의 데이터그램으로 잘라주어야 합니다.

여기서 각각의 잘린 데이터그램들의 헤더들은 위에서 나온 Flag와 Fragmentation Offset만 다르고 나머지는 모두 같습니다.
그럼 이 시점에서 다시 위에서 넘어간 부분들을 살펴보겠습니다.
5. Identification: 잘린 데이터그램들이 원래 같은 데이터그램이라는 것을 증명하기 위해 각각의 데이터그램들은 중복되지 않는 고유한 식별자들을 가지고 있습니다. 이를 위해 송신 측에서는 하나의 데이터그램을 보낼 때마다 카운터의 값을 1씩 증가시켜 고유한 식별자를 만들어냅니다.
6. Flag, Fragmentation Offset: 플래그 필드의 3개의 비트는 해당 데이터그램의 각각 다른 특징을 표현해줍니다. 가장 우측의 0번 비트는 항상 0이라는 값을 가지고, 그 옆의 1번 비트는 해당 데이터그램이 쪼개어질 수 있는지에 대한 여부에 따라 가능하다면 0, 그렇지 않다면 1을 가집니다.
혹시 쪼개어질 수 없는 데이터그램이 쪼개어져야 하는 상황이 오면, 송신자에게 상황을 알리고, 해당 데이터그램을 그냥 없애(Drop) 버립니다.
그리고 마지막으로 2번 비트는 단편화된 데이터그램들 사이에서 자신이 마지막 데이터그램인지의 여부를 알려줍니다. 다시 말해, 하나의 데이터그램이 다섯 개로 나누어졌다면, 앞에서부터 1~4번 데이터그램은 해당 비트가 0, 그리고 마지막 다섯 번째 데이터그램만 1을 가집니다.
이렇게 잘라져서 도착한 데이터그램들은 모두 같은 길을 거쳐 순서대로 도착했을 것이라는 보장을 할 수 없습니다. 실제로 트래픽 상황에 따라 서로 다른 길을 통해 목적지로 왔을 수 있고, 따라서 목적지에서 식별자를 확인해서 데이터그램들을 모아 보면 순서가 뒤죽박죽일 수 있습니다.
Fragmentation Offset은 이러한 경우에 순서를 맞추기 위해 사용됩니다. 정확히는 해당 데이터그램의 데이터가 가장 앞의 데이터로부터 얼마나 떨어져 있는지를 기록합니다. 당연히 첫 번째 데이터그램의 Offset에는 0이 쓰여 있을 것이고, 두 번째 데이터그램부터는 가장 처음으로부터 얼마나 떨어져 있는지를 계산하여 작성해줍니다.
그리고 이 정보들을 이용하여 목적지에서는 다시 원본 데이터그램으로 합쳐줍니다.
3. Error Control
마지막으로 헤더 체크섬에서 오류 제어는 어떻게 하는지 살펴보겠습니다. 해당 필드에서는 데이터 부분의 오류는 체크하지 않고, 단지 헤더에 오류가 있는지만을 확인합니다.
방법은 다음과 같습니다.
1. 데이터그램의 체크섬 필드를 0으로 만들어준다.
2. 헤더의 값들을 16비트씩 끊어서 나누어준다.
3. 이렇게 나눈 각각의 부분들을 모두 합해준다.
4. 이 합한 값에 1의 보수를 취해준다.
5. 이 값을 체크섬 필드에 저장한다.
6. 수신자는 받은 데이터그램의 헤더를 다시 16비트로 각각 나눈 뒤, 모두 합해준다.
7. 값이 1111111111111111이 나오면 오류가 없는 것으로, 그대로 받아들이고, 그렇지 않으면 해당 데이터그램은 오류가 있는 것으로 간주되어 폐기된다.
'전공공부 > 컴퓨터망 (Computer Network)' 카테고리의 다른 글
| [컴퓨터망] Network Layer (6) - DHCP (0) | 2021.02.01 |
|---|---|
| [컴퓨터망] Network Layer (5) - Subnet (3) | 2021.02.01 |
| [컴퓨터망] Network Layer (3) - Buffer Management (1) | 2021.01.28 |
| [컴퓨터망] Network Layer (2) - Switching Fabric (0) | 2021.01.28 |
| [컴퓨터망] Network Layer (1) - Routing & Forwarding (1) | 2021.01.26 |