Human Pose Estimation에 대한 프로젝트를 진행하려다보니 자연스럽게 HRNet이라는 CNN 아키텍처를 사용하게 되었습니다. 물론 코드야 그냥 깃에서 가져와서 돌리면 되는거지만, 어떤 구조인지는 한 번 알아보고 싶어 조금이나마 공부를 해보게 되었습니다.
컴퓨터 비전의 CNN 아키텍처들은 AlexNET으로부터 시작해 GoogLeNET, VGG NET, ResNET, DenseNET 등을 거치면서 발전해왔습니다. 그리고 이들을 잇는 모델로 2019년 HRNet이 등장했습니다.
대부분의 CNN 아키텍처들의 경우 High Resolution에서 Low Resolution으로 점점 해상도를 줄여나가는 방식이라면, HRNet은 High Resolution을 유지한 채로 병렬적으로 Low Resolution을 적용하는 방식입니다.

위의 VGG Net의 예와 같이, 대부분의 CNN 아키텍처들은 중간중간에 Pooling Layer를 삽입해주었기 때문에, 점진적으로 해상도가 떨어질 수밖에 없는 구조를 가지고 있습니다. (High-to-Low Convolutions in Series)
그리고 High Resolution Representation을 얻기 위해 Low Resolution Representation으로부터 복구하기도 합니다.

하지만 HRNet의 경우 High Resolution을 전체 프로세스 내내 유지하면서 층이 깊어질수록 점점 더 Low Resolution를 가지는 Feautre map을 병렬적으로 추가해주는 방식을 사용합니다. (Multi-resolution streams in parallel)

위의 방식을 통해 각 Subnetwork들이 각각의 Resolution에서 뽑아낸 Feature들의 정보를 받아 사용하기 때문에 정확도를 올릴 수 있습니다. 그리고 High Resolution Representation을 유지하기 때문에 Low Resolution Representation으로부터 복구할 필요도 없습니다.
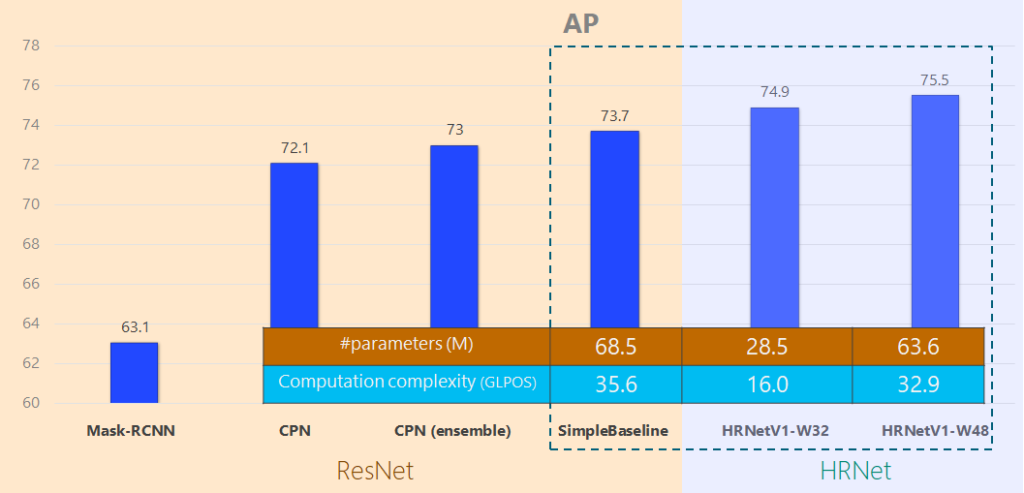
HRNet은 특히 Pose Estimation 분야에서 좋은 결과를 보여줍니다. 아래의 표에서 ResNet 기반의 Pose Estimation과의 비교 결과를 확인할 수 있습니다. 정확도 면에서 당연히 향상되었을 뿐 아니라, Parameter의 수와 복잡도를 ResNet에 비해 감소시켜서 연산량 마저 떨어뜨렸습니다. 이것이 제가 HRNet을 사용하게 된 이유이기도 하구요.
추가적으로 저는 HRNet을 아래의 깃허브 주소에서 받아 사용하였습니다.
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
'프로젝트 및 실습 > Pytorch (Computer Vision)' 카테고리의 다른 글
| [Pytorch] 분류기 뉴럴 네트워크 개발 일기 (2) - 모델 성능 향상 (0) | 2021.07.27 |
|---|---|
| [Pytorch] 분류기 뉴럴 네트워크 개발 일기 (1) - 모델 생성 (0) | 2021.07.23 |
| [Pytorch] Ubuntu 20.04에 Jupyter Notebook 설치 및 서버 컴퓨터에 원격 실행 (0) | 2021.07.16 |
| [Pytorch] Ubuntu 20.04에서 Pytorch 사용을 위한 환경 세팅 (0) | 2021.07.13 |